
一、将查询结果插入到其它表中
1. 思考
目前只有一个goods表,我们想要增加一个商品分类信息,比如:移动设备这个分类信息,只通过goods表无法完成商品分类的添加,那么如何实现添加商品分类信息的操作?
答案:
- 创建一个商品分类表,把goods表中的商品分类信息添加到该表中。
- 将goods表中的分类名称更改成商品分类表中对应的分类id
2. 创建商品分类表
-- 创建商品分类表
create table good_cates(
id int not null primary key auto_increment,
name varchar(50) not null
);
3. 把goods表中的商品分类添加到商品分类表
-- 查询goods表中商品的分类信息
select cate_name from goods group by cate_name;
-- 将查询结果插入到good_cates表中
insert into good_cates(name) select cate_name from goods group by cate_name;
-- 添加移动设备分类信息
insert into good_cates(name) values('移动设备');
说明:
- insert into .. select .. 表示: 把查询结果插入到指定表中,也就是表复制。
二、使用连接更新表中某个字段数据
1. 更新goods表中的商品分类信息
上一节课我们已经创建了一个商品分类表(good_cates),并完成了商品分类信息的插入,现在需要更新goods表中的商品分类信息,把商品分类名称改成商量分类id。
接下来我们实现第二步操作:
- 将goods表中的分类名称更改成商品分类表中对应的分类id
-- 查看goods表中的商品分类名称对应的商品分类id
select * from goods inner join good_cates on goods.cate_name = good_cates.name;
-- 把该语句中from 后的语句理解为一张虚表
update goods g inner join good_cates gc on g.cate_name=gc.name set g.cate_name=gc.id;三、创建表并给某个字段添加数据
1. 思考
上一节课我们完成了商品分类表(good_cates)的创建和商品分类信息的添加以及把商品表(goods)中的商品分类名称改成了对应的商品分类id,假如我们想要添加一个品牌,比如:双飞燕这个品牌信息,只通过goods表无法完成品牌信息的添加,那么如何实现添加品牌信息的操作?
答案:
- 创建一个品牌表,把goods表中的品牌信息添加到该表中。
- 将goods表中的品牌名称更改成品牌表中对应的品牌id
2. 创建品牌表
-- 查询品牌信息
select brand_name from goods group by brand_name;
-- 通过create table ...select来创建数据表并且同时插入数据
-- 创建商品分类表,注意: 需要对brand_name 用as起别名,否则name字段就没有值
create table good_brands (
id int unsigned primary key auto_increment,
name varchar(40) not null) select brand_name as name from goods group by brand_name;
说明:
- create table .. select 列名 .. 表示创建表并插入数据
3. 更新goods表中的品牌信息
-- 将goods表中的品牌名称更改成品牌表中对应的品牌id
update goods as g inner join good_brands gb on g.brand_name = gb.name set g.brand_name = gb.id;四、修改goods表结构
目前我们已经把good表中的商品分类和品牌信息已经更改成了商品分类id和品牌id,接下来需要把 cate_name 和 brand_name 字段分别改成 cate_id和 brand_id 字段,类型都改成int类型
-- 查看表结构
desc goods;
-- 通过alter table语句修改表结构
alter table goods change cate_name cate_id int not null, change brand_name brand_id int not null;
说明:
- alert table 可以同时修改多个字段信息
五、PyMySQL的使用
1. 思考
如何实现将100000条数据插入到MySQL数据库?
答案:
如果使用之前学习的MySQL客户端来完成这个操作,那么这个工作量无疑是巨大的,我们可以通过使用程序代码的方式去连接MySQL数据库,然后对MySQL数据库进行增删改查的方式,实现10000条数据的插入,像这样使用代码的方式操作数据库就称为数据库编程。
2. Python程序操作MySQL数据库
安装pymysql第三方包:
sudo pip3 install pymysql
说明:
- 安装命令使用 sudo pip3 install 第三方包名
- 卸载命令使用 sudo pip3 uninstall 第三方包
- 大家现在使用的虚拟机已经安装了这个第三方包,可以使用: pip3 show pymysql 命令查看第三方包的信息
- pip3 list 查看使用pip命令安装的第三方包列表
pymysql的使用:
1、导入 pymysql 包
import pymysql2、创建连接对象
调用pymysql模块中的connect()函数来创建连接对象,代码如下:
conn=connect(参数列表)
* 参数host:连接的mysql主机,如果本机是'localhost'
* 参数port:连接的mysql主机的端口,默认是3306
* 参数user:连接的用户名
* 参数password:连接的密码
* 参数database:数据库的名称
* 参数charset:通信采用的编码方式,推荐使用utf8
连接对象操作说明:
- 关闭连接 conn.close()
- 提交数据 conn.commit()
- 撤销数据 conn.rollback()
3、获取游标对象
获取游标对象的目标就是要执行sql语句,完成对数据库的增、删、改、查操作。代码如下:
# 调用连接对象的cursor()方法获取游标对象
cur =conn.cursor()游标操作说明:
- 使用游标执行SQL语句: execute(operation [parameters ]) 执行SQL语句,返回受影响的行数,主要用于执行insert、update、delete、select等语句
- 获取查询结果集中的一条数据:cur.fetchone()返回一个元组, 如 (1,’张三’)
- 获取查询结果集中的所有数据: cur.fetchall()返回一个元组,如((1,’张三’),(2,’李四’))
- 关闭游标: cur.close(),表示和数据库操作完成
4、pymysql完成数据的查询操作
import pymysql
# 创建连接对象
conn = pymysql.connect(host='localhost', port=3306, user='root', password='mysql',database='python', charset='utf8')
# 获取游标对象
cursor = conn.cursor()
# 查询 SQL 语句
sql = "select * from students;"
# 执行 SQL 语句 返回值就是 SQL 语句在执行过程中影响的行数
row_count = cursor.execute(sql)
print("SQL 语句执行影响的行数%d" % row_count)
# 取出结果集中一行数据, 例如:(1, '张三')
# print(cursor.fetchone())
# 取出结果集中的所有数据, 例如:((1, '张三'), (2, '李四'), (3, '王五'))
for line in cursor.fetchall():
print(line)
# 关闭游标
cursor.close()
# 关闭连接
conn.close()5、pymysql完成对数据的增删改
import pymysql
# 创建连接对象
conn = pymysql.connect(host='localhost', port=3306, user='root', password='mysql',database='python', charset='utf8')
# 获取游标对象
cursor = conn.cursor()
try:
# 添加 SQL 语句
# sql = "insert into students(name) values('刘璐'), ('王美丽');"
# 删除 SQ L语句
# sql = "delete from students where id = 5;"
# 修改 SQL 语句
sql = "update students set name = '王铁蛋' where id = 6;"
# 执行 SQL 语句
row_count = cursor.execute(sql)
print("SQL 语句执行影响的行数%d" % row_count)
# 提交数据到数据库
conn.commit()
except Exception as e:
# 回滚数据, 即撤销刚刚的SQL语句操作
conn.rollback()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()说明:
- conn.commit() 表示将修改操作提交到数据库
- conn.rollback() 表示回滚数据
6、防止SQL注入
什么是SQL注入?
用户提交带有恶意的数据与SQL语句进行字符串方式的拼接,从而影响了SQL语句的语义,最终产生数据泄露的现象。
如何防止SQL注入?
SQL语句参数化
- SQL语言中的参数使用%s来占位,此处不是python中的字符串格式化操作
- 将SQL语句中%s占位所需要的参数存在一个列表中,把参数列表传递给execute方法中第二个参数
防止SQL注入的示例代码:
from pymysql import connect
def main():
find_name = input("请输入物品名称:")
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='jing_dong',charset='utf8')
# 获得Cursor对象
cs1 = conn.cursor()
# 非安全的方式
# 输入 ' or 1 = 1 or ' (单引号也要输入)
# sql = "select * from goods where name='%s'" % find_name
# print("""sql===>%s<====""" % sql)
# # 执行select语句,并返回受影响的行数:查询所有数据
# count = cs1.execute(sql)
# 安全的方式
# 构造参数列表
params = [find_name]
# 执行select语句,并返回受影响的行数:查询所有数据
count = cs1.execute("select * from goods where name=%s", params)
# 注意:
# 如果要是有多个参数,需要进行参数化
# 那么params = [数值1, 数值2....],此时sql语句中有多个%s即可
# %s 不需要带引号
# 打印受影响的行数
print(count)
# 获取查询的结果
# result = cs1.fetchone()
result = cs1.fetchall()
# 打印查询的结果
print(result)
# 关闭Cursor对象
cs1.close()
# 关闭Connection对象
conn.close()
if __name__ == '__main__':
main()说明:
- execute方法中的 %s 占位不需要带引号
六、事务
1. 事务的介绍
事务就是用户定义的一系列执行SQL语句的操作, 这些操作要么完全地执行,要么完全地都不执行, 它是一个不可分割的工作执行单元。
事务的使用场景:
在日常生活中,有时我们需要进行银行转账,这个银行转账操作背后就是需要执行多个SQL语句,假如这些SQL执行到一半突然停电了,那么就会导致这个功能只完成了一半,这种情况是不允许出现,要想解决这个问题就需要通过事务来完成。
2. 事务的四大特性
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
原子性:
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
一致性:
数据库总是从一个一致性的状态转换到另一个一致性的状态。(在前面的例子中,一致性确保了,即使在转账过程中系统崩溃,支票账户中也不会损失200美元,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。)
隔离性:
通常来说,一个事务所做的修改操作在提交事务之前,对于其他事务来说是不可见的。(在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外的一个账户汇总程序开始运行,则其看到支票帐户的余额并没有被减去200美元。)
持久性:
一旦事务提交,则其所做的修改会永久保存到数据库。
说明:
事务能够保证数据的完整性和一致性,让用户的操作更加安全。
3. 事务的使用
在使用事务之前,先要确保表的存储引擎是 InnoDB 类型, 只有这个类型才可以使用事务,MySQL数据库中表的存储引擎默认是 InnoDB 类型。
表的存储引擎说明:
表的存储引擎就是提供存储数据一种机制,不同表的存储引擎提供不同的存储机制。
汽车引擎效果图:


说明:
- 不同的汽车引擎,提供的汽车动力也是不同的。
查看MySQL数据库支持的表的存储引擎:
-- 查看MySQL数据库支持的表的存储引擎
show engines;
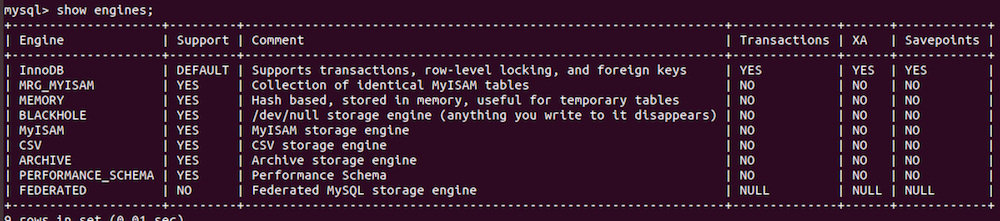
说明:
- 常用的表的存储引擎是 InnoDB 和 MyISAM
- InnoDB 是支持事务的
- MyISAM 不支持事务,优势是访问速度快,对事务没有要求或者以select、insert为主的都可以使用该存储引擎来创建表
查看goods表的创表语句:
-- 选择数据库
use jing_dong;
-- 查看goods表
show create table goods;
mysql root@(none):jing_dong> show create table goods;
+-------+--------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------+
| goods | CREATE TABLE `goods` ( |
| | `id` int(10) unsigned NOT NULL AUTO_INCREMENT, |
| | `name` varchar(150) NOT NULL, |
| | `cate_id` int(10) unsigned NOT NULL, |
| | `brand_id` int(10) unsigned NOT NULL, |
| | `price` decimal(10,3) NOT NULL DEFAULT '0.000', |
| | `is_show` bit(1) NOT NULL DEFAULT b'1', |
| | `is_saleoff` bit(1) NOT NULL DEFAULT b'0', |
| | PRIMARY KEY (`id`) |
| | ) ENGINE=InnoDB AUTO_INCREMENT=25 DEFAULT CHARSET=utf8 |
+-------+--------------------------------------------------------+
说明:
- 通过创表语句可以得知,goods表的存储引擎是InnoDB。
- 修改表的存储引擎使用: alter table 表名 engine = 引擎类型;比如: alter table students engine = ‘MyISAM’;
开启事务:
begin;
或者
start transaction;
说明:
- 开启事务后执行修改命令,变更数据会保存到MySQL服务端的缓存文件中,而不维护到物理表中
- MySQL数据库默认采用自动提交(autocommit)模式,如果没有显示的开启一个事务,那么每条sql语句都会被当作一个事务执行提交的操作
- 当设置autocommit=0就是取消了自动提交事务模式,直到显示的执行commit和rollback表示该事务结束。
- set autocommit = 0 表示取消自动提交事务模式,需要手动执行commit完成事务的提交
- set autocommit = 0; insert into students(name) values(‘刘三峰’); — 需要执行手动提交,数据才会真正添加到表中, 验证的话需要重新打开一个连接窗口查看表的数据信息,因为是临时关闭自动提交模式 commit — 重新打开一个终端窗口,连接MySQL数据库服务端 mysql -uroot -p — 然后查询数据,如果上个窗口执行了commit,这个窗口才能看到数据 select * from students;
- 提交事务:
- 将本地缓存文件中的数据提交到物理表中,完成数据的更新。
- commit;
- 回滚事务:
- 放弃本地缓存文件中的缓存数据, 表示回到开始事务前的状态
- rollback;
- 事务演练的SQL语句:
- begin; insert into students(name) values(‘李白’); — 查询数据,此时有新增的数据, 注意: 如果这里后续没有执行提交事务操作,那么数据是没有真正的更新到物理表中 select * from students; — 只有这里提交事务,才把数据真正插入到物理表中 commit; — 新打开一个终端,重新连接MySQL数据库,查询students表,这时没有显示新增的数据,说明之前的事务没有提交,这就是事务的隔离性 — 一个事务所做的修改操作在提交事务之前,对于其他事务来说是不可见的 select * from students;
七、索引
1. 索引的介绍
索引在MySQL中也叫做“键”,它是一个特殊的文件,它保存着数据表里所有记录的位置信息,更通俗的来说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
应用场景:
当数据库中数据量很大时,查找数据会变得很慢,我们就可以通过索引来提高数据库的查询效率。
2. 索引的使用
查看表中已有索引:
show index from 表名;
说明:
- 主键列会自动创建索引
索引的创建:
-- 创建索引的语法格式
-- alter table 表名 add index 索引名[可选](列名, ..)
-- 给name字段添加索引
alter table classes add index my_name (name);
说明:
- 索引名不指定,默认使用字段名
索引的删除:
-- 删除索引的语法格式
-- alter table 表名 drop index 索引名
-- 如果不知道索引名,可以查看创表sql语句
show create table classes;
alter table classes drop index my_name;
3. 案例-验证索引查询性能
创建测试表testindex:
create table test_index(title varchar(10));
向表中插入十万条数据:
from pymysql import connect
def main():
# 创建Connection连接
conn = connect(host='localhost',port=3306,database='python',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
cursor = conn.cursor()
# 插入10万次数据
for i in range(100000):
cursor.execute("insert into test_index values('ha-%d')" % i)
# 提交数据
conn.commit()
if __name__ == "__main__":
main()
验证索引性能操作:
-- 开启运行时间监测:
set profiling=1;
-- 查找第1万条数据ha-99999
select * from test_index where title='ha-99999';
-- 查看执行的时间:
show profiles;
-- 给title字段创建索引:
alter table test_index add index (title);
-- 再次执行查询语句
select * from test_index where title='ha-99999';
-- 再次查看执行的时间
show profiles;
4. 联合索引
联合索引又叫复合索引,即一个索引覆盖表中两个或者多个字段,一般用在多个字段一起查询的时候。
-- 创建teacher表
create table teacher
(
id int not null primary key auto_increment,
name varchar(10),
age int
);
-- 创建联合索引
alter table teacher add index (name,age);
联合索引的好处:
- 减少磁盘空间开销,因为每创建一个索引,其实就是创建了一个索引文件,那么会增加磁盘空间的开销。
5. 联合索引的最左原则
在使用联合索引的时候,我们要遵守一个最左原则,即index(name,age)支持 name 、name 和 age 组合查询,而不支持单独 age 查询,因为没有用到创建的联合索引。
最左原则示例:
-- 下面的查询使用到了联合索引
select * from stu where name='张三' -- 这里使用了联合索引的name部分
select * from stu where name='李四' and age=10 -- 这里完整的使用联合索引,包括 name 和 age 部分
-- 下面的查询没有使用到联合索引
select * from stu where age=10 -- 因为联合索引里面没有这个组合,只有 name | name age 这两种组合
说明:
- 在使用联合索引的查询数据时候一定要保证联合索引的最左侧字段出现在查询条件里面,否则联合索引失效
6. MySQL中索引的优点和缺点和使用原则
- 优点:
- 加快数据的查询速度
- 缺点:
- 创建索引会耗费时间和占用磁盘空间,并且随着数据量的增加所耗费的时间也会增加
- 使用原则:
- 通过优缺点对比,不是索引越多越好,而是需要自己合理的使用。
- 对经常更新的表就避免对其进行过多索引的创建,对经常用于查询的字段应该创建索引,
- 数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
- 在一字段上相同值比较多不要建立索引,比如在学生表的”性别”字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可是建立索引
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至2705686032@qq.com 举报,一经查实,本站将立刻删除。原文转载: 原文出处:
